




The Secret Life of Photons
Simulating 2D Light Transport

As a small breather from my usual rendering work, I worked on a physically based 2D rendering side project over the past few months. The idea of this project was to build a light transport simulation using the same mathematical tools used in academic and movie production renderers, but in a simplified 2D setting. The 2D setting allows for faster render times and a more accessible way of understanding and interacting with light, even for people with no prior knowledge or interest in rendering.
This article describes some of the conceptual and mathematical background that went into this project, as well as a few of the more interesting implementation details. Parts of this article may be pretty boring if you don't have a rendering background, so feel free to skip text at will or directly try out the WebGL implementation.
Initially, this project was implemented purely in C++, but eventually I realized I would be able to reach a lot more people if they didn't have to download and compile an executable. However, after reimplementing it in JavaScript it became apparent that JS was more on the slow side of things. Ultimately I had to offload the heavy lifting onto the GPU, which came at the cost of narrowing the user base to those supporting WebGL and float textures (i.e. those on Desktop with a recent browser). If it doesn't run on your platform, sorry!
The JavaScript source code is freely available in a Github repo under a permissive open source license, so feel free to modify and redistribute. The C++ code does not quite live up to the same quality standards, and I'm not planning to release it in the near future.
Introduction
Light transport theory in Computer Graphics has a comparatively short history, and has gone from a curious academic tool to the workhorse behind full blown movie production rendering within just a few decades. As a small disclaimer to those closer to physics than computer graphics, the light transport we will be looking at in this article is a simplified model of light based on geometric optics, which has become very popular in computer graphics. We will not be able to model wave or quantum optics effects, as these are a lot more difficult to simulate at a large scale.
The main motivation of this project was to build a tool that allowed us to visualize the "hidden" behavior of light that is normally obscured in 3D light transport. To illustrate what I mean by this, consider this rendered image of a Cornell Box with a glass sphere inside (left). At first glance, nothing particularly interesting is happening in this scene; that is, until we add a small amount of scattering gas to the box (right): Suddenly a caustic appears in midair, caused by light focused by the refractive sphere.


A simple Cornell Box with a point light and a refractive sphere (left). Adding in a small amount of scattering gas makes the evolution of the caustic behind the sphere visible (right).
This is very typical: Especially when refraction is involved, light tends to move along intricate paths through the scene. However, we are normally only able to perceive light when it hits a surface and scatters towards the camera, hiding a lot of the interesting patterns. By inserting a scattering gas, we were able to make some of this behavior visible. This is by far not an optimal solution though: It's computationally expensive, and the gas itself influences the light transport, blurring away some of the details.
A more useful approach is to slightly modify the rendering problem and visualize a quantity known as the fluence instead. We will introduce a more rigorous definition later, but the fluence is essentially the average amount of light passing through a point, and is defined almost everywhere in space (not just surfaces), allowing us to "see" the light between surfaces. Unfortunately, rendering this quantity in 3D is fairly computationally expensive, and still doesn't solve all of our problems: Because the rendered image is only 2D, visualizing a 3D fluence essentially blends everything together along one dimension, and the final rendered image may become very difficult to understand.
To fit the fluence onto a 2D image, I ultimately decided to throw away one dimension of the fluence and solve a 2D rendering problem instead. This 2D fluence is a lot easier to visualize and understand.
In the following sections, I will go a little bit more into how we can mathematically set up the problem we want to solve, before modifying a Monte Carlo rendering method to fit our purpose. Through correlating the pixel estimates and mollifying part of the problem, we will arrive at a rendering algorithm that's extremely easy to understand: We simply shoot photons of different wavelengths from a light source, simulate their interactions with surfaces and record their paths on an image. It's not an optimal algorithm (it can in fact be made to converge arbitrarily slow), but it's simple enough to understand even for audiences without a rendering background. It also maps nicely to GPU hardware - with some issues, which I'll go into at the end of this article.
Related Work
2D light transport is not a novel idea and has been the focus of research by a variety of groups in a variety of contexts. There are two different ways we can go about setting up the transport problem: Using an embedded model or an intrinsic model.
In the embedded model, the visualized image is simply a 2D plane embedded into a 3D world (i.e. a "Flatland" model). In such an approach, we can render a 2D scene by extruding all 2D objects along the 3rd dimension (e.g. turning circles into infinite cylinders). Then we solve for the 3D light transport in the resulting scene, and display a 2D slice out of the computed solution. This way, we can trivially reuse existing solvers for 3D light transport, only with a slightly different camera model. Although straightforward, such an approach suffers from inconsistency issues, and doesn't actually make the problem easier: We still have to solve a 3D transport problem in all its ugliness.
A different approach is the intrinsic model, in which we rederive radiometry in two dimensions, leading to a 2D model that is self-contained and does not rely on a 3D embedding. Luckily, most of the difficult work has already been done for us by Jarosz et al. in the paper Theory, Analysis and Applications of 2D Global Illumination, and most of this project will be based on their work.
If you're familiar with physically based 3D rendering, here are the good news: Most of the radiometric quantities remain very similar when going from 3D to 2D, only with slightly different units (  instead of
instead of  , radians instead of steradians, and so forth). The bad news is that all surface reflectance models (BRDFs) will have to be rederived in 2D, and some of them don't actually have a direct 2D analog. More of that later.
, radians instead of steradians, and so forth). The bad news is that all surface reflectance models (BRDFs) will have to be rederived in 2D, and some of them don't actually have a direct 2D analog. More of that later.
The Mathematics of 2D Light Transport
In this section, we will briefly review 2D light transport following Jarosz et al. and write down the equation we need to solve in order to render an image. Afterwards, we will discuss different solution methods and their drawbacks before deriving the algorithm I used for this project. In order to keep things short I will assume some background in Computer Graphics and mainly highlight differences to 3D light transport. If the notation does not make sense to you, feel free to keep this section.
Similar to 3D light transport, the main quantity of interest is the radiance. We will split the radiance into two different functions: the incident radiance  and the exitant radiance
and the exitant radiance  (the arrows denote direction of light flow). The two are related by
(the arrows denote direction of light flow). The two are related by
}{-\Dir},") where
where ") is the raytracing function, which returns the closest curve point along the ray
is the raytracing function, which returns the closest curve point along the ray  with
with  . If you've implemented a raytracer before, this function will be very familiar.
. If you've implemented a raytracer before, this function will be very familiar.
The incident radiance is defined anywhere in space, whereas the exitant radiance is only defined on curves. We related the two by stating that the radiance arriving from direction  at a point
at a point  is equivalent to the radiance leaving the closest curve along the ray
is equivalent to the radiance leaving the closest curve along the ray  , i.e. light only interacts with curves, not empty space. You will notice that we assumed absence of participating media here (i.e. light moves in a vacuum), which means that radiance stays constant along rays. For a complete model we would have to relate the incident and exitant radiance using the equation of radiative transfer, but for simplicity we will focus on the vacuum case for now (it will also result in a more efficient rendering algorithm). I will briefly discuss participating media at the end.
, i.e. light only interacts with curves, not empty space. You will notice that we assumed absence of participating media here (i.e. light moves in a vacuum), which means that radiance stays constant along rays. For a complete model we would have to relate the incident and exitant radiance using the equation of radiative transfer, but for simplicity we will focus on the vacuum case for now (it will also result in a more efficient rendering algorithm). I will briefly discuss participating media at the end.
The definition of the exitant radiance can be written down in recursive form as the familiar rendering equation:
 \Li{\Point}{\Dir_i} |\Dir_i \cdot \Normal(\Point)| \Measure\Dir_i.") The right-hand side looks almost identical to the 3D case and consists of a source term
The right-hand side looks almost identical to the 3D case and consists of a source term  (the emitted radiance) as well as a reflection term. Here,
(the emitted radiance) as well as a reflection term. Here, ") stands for the curve normal at point
stands for the curve normal at point  ,
,  is the hemicircle of directions centered on
is the hemicircle of directions centered on ") , and
, and |") is the foreshortening factor. We also used
is the foreshortening factor. We also used ") , which is the bidirectional reflectance distribution function (BRDF). We neglected transmissive surfaces here for simplicity, but the reflected radiance for the BSDF case looks almost identical.
, which is the bidirectional reflectance distribution function (BRDF). We neglected transmissive surfaces here for simplicity, but the reflected radiance for the BSDF case looks almost identical.
To formalize our rendering objective, let us begin by writing down the definition of the quantity of interest, which is the fluence:
 = \int_{\Circle} \Li{\Point}{\Dir} \Measure\Dir.") Our end goal is to render an image, i.e. we need to evaluate the fluence at
Our end goal is to render an image, i.e. we need to evaluate the fluence at  points
points  , one for each pixel. We will denote the fluence measurement associated with the
, one for each pixel. We will denote the fluence measurement associated with the  -th pixel as
-th pixel as ") .
.
Solutions to the 2D Light Transport Problem
As expected, evaluating this expression is difficult and we can not derive a closed-form solution in the general case. For 3D renderers, the most successful methods are based on Monte Carlo integration, which we will use as well. However, computing the fluence comes with slightly different constraints and we'll ultimately end up with a slightly different rendering method, as we will see later. To get an idea for why that is, let's write down a straightforward Monte Carlo estimator for the fluence:
 \approx \sum_{i=1}^N \frac{\Li{\Point}{\vec{X}_i}}{\mathrm{pdf}(\vec{X}_i)}.") Here,
Here,  is a realization of a random variable
is a realization of a random variable  of unit directions, distributed with probability density function
of unit directions, distributed with probability density function ") . Using the definition of the incident radiance, we can rewrite this as
. Using the definition of the incident radiance, we can rewrite this as
 \approx \sum_{i=1}^N \frac{\Lo{\Trace(\Point, -\vec{X}_i)}{\vec{X}_i)}}{\mathrm{pdf}(\vec{X}_i)}.") In simpler terms, to estimate the fluence at a given pixel, we simply generate a set of random directions, raytrace until we hit the nearest curve, evaluate the radiance there and average the result.
In simpler terms, to estimate the fluence at a given pixel, we simply generate a set of random directions, raytrace until we hit the nearest curve, evaluate the radiance there and average the result.
As we can see, we've reduced our slightly unusual problem of computing the fluence to the well-researched case of computing the radiance on surfaces. We could now go and plug in a standard light transport algorithm such as path tracing to estimate the exitant radiance, and use the result to construct an estimator for the fluence as shown above. Unfortunately, there are a few problems with this approach. To create interesting looking images, we are looking for sharp caustics and similar effects, so ideally we want to use perfectly specular dielectrics in conjunction with singular light sources, such as point lights or directional lights. Using an unbiased estimator, it is then impossible to sample a valid light path that connects a pixel to a point light through a refractive object - we'll never be able to render such effects!
Clearly, some kind of mollification is required. Not even photon mapping would completely work here, since it cannot sample paths without a vertex on a diffuse surface. These paths are very prominent for our use case of rendering the fluence, so an additional mollifier such as Path Space Regularization would be required. Alternatively, we can slightly restate our initial problem and use a different measurement instead. Rather than evaluating the fluence at a single point (a pixel), we'll average it over an area:
 \Fluence(\Point) \Measure\Point.") Here
Here ") is a filter kernel associated with the
is a filter kernel associated with the  -th pixel and
-th pixel and  is the kernel support. A different way of looking at this is that we're simply inserting a pixel reconstruction filter into the measurement (which is a good thing!). Ideally we would use a reconstruction filter with "good" properties, such as the Mitchell-Netravali filter or a Gaussian. However, we will use the simplest (and the worst) reconstruction filter, a box filter, for now. The reasons for this choice will become apparent in a bit.
is the kernel support. A different way of looking at this is that we're simply inserting a pixel reconstruction filter into the measurement (which is a good thing!). Ideally we would use a reconstruction filter with "good" properties, such as the Mitchell-Netravali filter or a Gaussian. However, we will use the simplest (and the worst) reconstruction filter, a box filter, for now. The reasons for this choice will become apparent in a bit.
For a forward path tracer, this modification of the problem statement didn't actually make things easier - the only difference is that we now first sample a point within the support of the filter kernel before performing path tracing as usual, which has the same issues with caustics as before. However, having non-singular measurement locations makes it possible to sample light transport in reverse: Light tracing!
With light tracing, instead of starting at the measurement location, we sample the emission term  to get the root of the light path and then bounce through the scene as a path tracer would. Whenever the light path crosses the kernel support
to get the root of the light path and then bounce through the scene as a path tracer would. Whenever the light path crosses the kernel support  , we convolve the radiance it carries with the reconstruction filter
, we convolve the radiance it carries with the reconstruction filter  along the path and add the result to the pixel estimate. In other words, we splat the path segment to the pixel.
along the path and add the result to the pixel estimate. In other words, we splat the path segment to the pixel.
Unfortunately, this is an extremely inefficient algorithm: The probability of a sampled light path crossing the filter support of a particular measurement  is extremely small. This problem arises in part because we only looked at a single pixel estimate in isolation so far, since that is what we're used to from rendering in 3D. However, if we look at the big picture, we can see that a single light path crosses a lot of pixels in its lifetime, even if it doesn't necessarily cross the
is extremely small. This problem arises in part because we only looked at a single pixel estimate in isolation so far, since that is what we're used to from rendering in 3D. However, if we look at the big picture, we can see that a single light path crosses a lot of pixels in its lifetime, even if it doesn't necessarily cross the  -th pixel.
-th pixel.
Therefore, we can make this algorithm a lot more efficient by letting a sample contribute to more than one estimate. Taking this to the extreme, we force all pixels to share the same sample pool, correlating all of the estimates. In other words, whenever we trace a light path, we convolve it with all reconstruction filters that touch a path segment and add the results to the picture.
A lot of people probably see where this is going, and yes: This is rasterization! If we trace a light path and draw all of the path segments as lines with additive blending into an image, this is equivalent to taking a single sample of the fluence and adding it do all pixel estimates at once. This also explains why we would want to choose a box reconstruction filter: It so happens that hardware exists which is capable of drawing an incredible amount of lines with additive blending very quickly - the GPU! - but it can only really do that with a box reconstruction filter (and not even that, as we will see later). Therefore, using a box filter we can efficiently estimate a fluence image by tracing a large amount of light paths and accumulating them in a single image.
Discussion
A good thing about this algorithm is that it falls into the class of analog algorithms: The algorithmic solution directly corresponds to the physical process that is being simulated. These algorithms are very intuitive - I could have replaced all of the Monte Carlo talk with "we're going to shoot a bunch of photons and draw them into an image" and the majority of people would have understood the program. Even someone without prior knowledge of offline rendering will come up with such a solution, and there are in fact a few projects such as Zen Photon that do something similar.
However, it's important to understand that analog solutions are not necessarily optimal, and moving outside the physically intuitive design space can result in faster algorithms. Therefore, it's worth spending some time analyzing this solution and how it could be improved.
First off, it's important to realize that making a single light path contribute to all pixel estimates means trading noise for correlation. The individual pixel estimates are a lot less noisy, but all pixels that share the same light path now have correlated estimates: The residual error in the image is no longer white noise (which the human visual system can blend out pretty well), but it has structure (the "noise" is now line-shaped). It also means that if we get a bad sample - a firefly path - it will "poison" all pixel estimates it touches instead of just one estimate. However, in our case the efficiency gain from rendering lines outweighs the structured error, and visually the image converges faster even though the error is worse. Also, because all we do is light tracing, most of the terms of the path contribution are very easy to sample, and we can avoid fireflies for the most part.
Second, light tracing is actually a fairly poor algorithm for rendering "easy" scenes. Consider the example below, which simply renders the fluence of a point light in an empty scene. Naive path tracing with next event estimation converges with a single sample per pixel, whereas light tracing shows considerable artifacts at the same sample count:


Fluence of a point light. Path tracing (left) converges to a noise-free solution with one sample per pixel. Light tracing (right) still has considerable noise at an equal number of rays traced.
Even more concerning, light tracing can be made arbitrarily worse by moving the light source further away. Therefore, we should expect considerable image improvements if we even just combine unidirectional path tracing and light tracing using multiple importance sampling, and more sophisticated bidirectional combinations are most likely possible.
Since my implementation is GPU based, combining two sampling strategies is pretty inconvenient, and I did not implement such an approach in my WebGL demo. However, for a more serious/robust application of this (e.g. 2D lightmap generation for games), writing a slightly smarter implementation would most likely be beneficial.
Reflectance Models in 2D
The most inconvenient change from 3D to 2D light transport is the fact that all material models (BRDFs) need to be rederived - the change of integration domain (hemicircle instead of hemisphere) means that we need different normalization constants and different sampling routines. Maybe surprisingly, for some BRDFs the normalization factor does not exist in closed form in 2D. The BRDFs presented here have ideal sample strategies, i.e. the sample weight is always 1. This means that we never actually need to evaluate any of these BRDFs, we only need to sample them. This section will be a bit more hands-on, in that I will post sampling pseudo-code for each material model presented in this section.
Preliminaries
A BRDF ") in 2D is a two-dimensional function of two unit directions
in 2D is a two-dimensional function of two unit directions  and
and  that gives us information about the density of light arriving from
that gives us information about the density of light arriving from  that is reradiated into direction
that is reradiated into direction  . In order for it to make sense physically, it has to fulfill a number of properties - for example, it can never be negative, and it must integrate to less or equal to one (a surface cannot reflect more light than it receives), i.e.
. In order for it to make sense physically, it has to fulfill a number of properties - for example, it can never be negative, and it must integrate to less or equal to one (a surface cannot reflect more light than it receives), i.e.
 |N(\Point)\cdot\Dir_i| \Measure\Dir_i \leq 1") must hold for all
must hold for all  . If the integral is less than one, the material absorbs energy (which may or may not be what we want). To derive a BRDF we will usually start off with a function that has the shape that we want, but it does not integrate to 1 (i.e. it's not a BRDF yet). The act of normalization is then to figure out the correct scale factor so that it does integrate to the correct number.
. If the integral is less than one, the material absorbs energy (which may or may not be what we want). To derive a BRDF we will usually start off with a function that has the shape that we want, but it does not integrate to 1 (i.e. it's not a BRDF yet). The act of normalization is then to figure out the correct scale factor so that it does integrate to the correct number.
To make things simple, we define the BRDF within a local coordinate system, where the vector ") corresponds to the curve normal
corresponds to the curve normal ") in the global coordinate system, and
in the global coordinate system, and ") corresponds to the curve tangent. This allows us to define
corresponds to the curve tangent. This allows us to define  and
and  in terms of two angles,
in terms of two angles,  and
and  in
in ![[-\pi/2, \pi/2]](prerendered/inline-45-1.png "[-\pi/2, \pi/2]") , using the relation
, using the relation
 \Dir_o &= (\sin\theta_o,\;\cos\theta_o).") The hemicircular integral can then be written more conveniently as
The hemicircular integral can then be written more conveniently as
 \cos\theta_i \Measure\theta_i \leq 1.")
Smooth Mirrors and Dielectrics
Perfectly specular mirrors and dielectrics are probably the simplest materials we can simulate that still look interesting. Luckily the law of reflection and refraction already operate within a 2D plane, so their associated shading models stay largely the same in 2D compared to 3D.
I will not write down the BRDFs for these materials explicitly, as they involve Dirac deltas in strange measures and are all kinds of painful. If you're interested in the details, I can recommend Wenzel Jakob's Dissertation, but for now we will avoid this discussion entirely and directly write down the sampling methods.
A perfectly smooth mirror concentrates all reflected light into a single direction  , which is easily computed from the law of reflection. In 2D, it is simply
, which is easily computed from the law of reflection. In 2D, it is simply
.") A perfectly smooth dielectric (such as polished glass) will split light into two different directions: The reflected direction
A perfectly smooth dielectric (such as polished glass) will split light into two different directions: The reflected direction  , and the refracted direction
, and the refracted direction  , computed using Snell's law with
, computed using Snell's law with
,") where
where  is the refraction coefficient associated with the intersected curve. The refraction coefficient is related to a physical property of the two materials that touch the curve, and we will discuss it in more detail in the next section. The ratio with which light is split between these two directions is determined by the Fresnel equations.
is the refraction coefficient associated with the intersected curve. The refraction coefficient is related to a physical property of the two materials that touch the curve, and we will discuss it in more detail in the next section. The ratio with which light is split between these two directions is determined by the Fresnel equations.
Sampling these BRDFs is very simple. For a mirror, there is only one possible direction outgoing light can take, and its sampling method is
vec2 sampleMirror(vec2 w_o) {
return vec2(-w_o.x, w_o.y);
}
For a dielectric, we first probabilistically decide whether to reflect or to refract, depending on the Fresnel coefficient. The rest follows similar to the mirror case:
vec2 sampleDielectric(vec2 w_o, float ior) {
float eta = w_o.y < 0.0 ? ior : 1.0/ior;
float Fr = dielectricReflectance(eta, w_o);
if (rand() < Fr)
return vec2(-w_o.x, w_o.y);
else
return vec2(-w_o.x*eta, sqrt(1.0 - eta*eta*w_o.x*w_o.x)*-sign(w_o.y));
}
Here, dielectricReflectance evaluates the Fresnel equations for the given refraction coefficient and incident direction, and is omitted here for brevity. Example renders of the mirror and dielectric BRDFs are shown below.


A beam of light striking a flat surface with a mirror BRDF (left) and a dielectric BRDF (right).
Refraction Coefficients
The refraction coefficient  of an interface between two materials is equal to the ratio of the indices of refraction,
of an interface between two materials is equal to the ratio of the indices of refraction,  and
and  , of the two materials. The index of refraction is a physical property that can be measured, and tabulated values for many materials are available online, such as in this table on Wikipedia.
, of the two materials. The index of refraction is a physical property that can be measured, and tabulated values for many materials are available online, such as in this table on Wikipedia.
Usually, the index of refraction is wavelength dependent - different frequencies of light are refracted differently, which is what causes effects such as dispersion. With the appropriate data, a spectral light tracer will be capable of modelling these effects.
Wavelength dependent indices of refraction can be modelled using the Sellmeier equation, which is a function of wavelength  :
:
 = \sqrt{1 + \frac{B_1\lambda^2}{\lambda^2 - C_1} + \frac{B_2\lambda^2}{\lambda^2 - C_2} + \frac{B_3\lambda^2}{\lambda^2 - C_3}}.") The coefficients
The coefficients  and
and  are parameters of this model and need to be obtained from numerical fits to measured data. Tables of these coefficients are available on websites such as RefractiveIndex.info, but unfortunately, real materials usually don't cause enough dispersion to look interesting. I took some artistic freedom and made up coefficients of a fantasy material that created interesting looking dispersion effects.
are parameters of this model and need to be obtained from numerical fits to measured data. Tables of these coefficients are available on websites such as RefractiveIndex.info, but unfortunately, real materials usually don't cause enough dispersion to look interesting. I took some artistic freedom and made up coefficients of a fantasy material that created interesting looking dispersion effects.
The images below demonstrate the difference between a dielectric material with monochromatic index of refraction and one with a spectrally varying index of refraction.


A dielectric sphere lit by a point light, once with monochrome index of refraction (left) and once with a spectrally varying index of refraction (right). Note the presence of colored fringes in the caustic on the right, an effect called dispersion.
Lambertian Reflection
The simplest non-singular BRDF we can make is a perfectly diffuse reflector, which is invariant with respect to the viewing angle. That is,
 = c,") where c is an unkown normalization constant. To compute this factor for a perfectly energy conserving surface, we insert the BRDF into the hemicircular integral
where c is an unkown normalization constant. To compute this factor for a perfectly energy conserving surface, we insert the BRDF into the hemicircular integral
 \cos\theta_i \Measure\theta_i &= \int_{-\pi/2}^{\pi/2} c \cos\theta_i \Measure\theta_i &= 2c,") directly leading to the conclusion that
directly leading to the conclusion that  . The Lambertian BRDF in 2D is then
. The Lambertian BRDF in 2D is then
 = \frac{1}{2}.") Note that this is different from the 3D case, where the normalization constant is
Note that this is different from the 3D case, where the normalization constant is  .
.
We now derive a sampling routine for the desired target distribution  \cos\theta_i") , which we will do using the inversion method. As a first step, we need to find a normalized target PDF in terms of
, which we will do using the inversion method. As a first step, we need to find a normalized target PDF in terms of  proportional to the target distribution. The BRDF-foreshortening product is already normalized in this case, and we can use it directly:
proportional to the target distribution. The BRDF-foreshortening product is already normalized in this case, and we can use it directly:
 = \Bsdf(\Dir_i \leftrightarrow \Dir_o) \cos\theta_i = \frac{\cos{\theta_i}}{2}.") The corresponding cumulative distribution function (CDF) is
The corresponding cumulative distribution function (CDF) is
 &= \int_{-\pi/2}^{\theta_i} \mathrm{pdf}(\theta) \Measure\theta &= \int_{-\pi/2}^{\theta_i} \frac{\cos{\theta}}{2} \Measure\theta &= \frac{1 + \sin\theta_i}{2}.") Inverting the CDF yields
Inverting the CDF yields
 &= \xi \frac{1 + \sin\theta_i}{2} &= \xi 1 + \sin\theta_i &= 2 \xi \theta_i &= \arcsin(2 \xi - 1),")
 = \arcsin(2 \xi - 1).")
Using some trigonometric identities, we arrive at a remarkably simple sampling routine for a perfectly diffuse surface in 2D:
vec2 sampleDiffuse(vec2 w_o) {
float xi = rand();
float sinThetaI = 2.0*xi - 1.0;
float cosThetaI = sqrt(1.0 - sinThetaI*sinThetaI);
return vec2(sinThetaI, cosThetaI);
}
where rand() returns a uniform random number in ") . An example of a rendered diffuse material is shown below.
. An example of a rendered diffuse material is shown below.

A diffuse material lit by a beam of light.
Phong Shading Model
Another simple and popular shading model is the Phong Shading Model (not to be confused with Phong shading). In 2D, we can write it as
 = c\; (\cos\theta_i\cos\theta_o - \sin\theta_i\sin\theta_o)^n,") where
where  is a normalization factor and
is a normalization factor and  is an exponent value that determines the glossiness of the material. To determine the normalization factor, we will look at the simplest case of normal incidence (i.e.
is an exponent value that determines the glossiness of the material. To determine the normalization factor, we will look at the simplest case of normal incidence (i.e.  ). We get
). We get
 \cos\theta_i \Measure\theta_i &= \int_{-\pi/2}^{\pi/2} c \cos\theta_i^n \cos\theta_i \Measure\theta_i &= \int_{-\pi/2}^{\pi/2} c \cos\theta_i^{n + 1} \Measure\theta_i &= c \frac{\sqrt{\pi}\;\Gamma\left(\frac{2 + n}{2}\right)}{\Gamma\left(\frac{3 + n}{2}\right)},") from which we obtain
from which we obtain
}{\sqrt{\pi}\;\Gamma\left(\frac{2 + n}{2}\right)}.") Here,
Here, ") is the Gamma function. This normalization factor is surprisingly inconvenient to compute! Compare against the normalization factor for the 3D Phong shading model (again at normal incidence):
is the Gamma function. This normalization factor is surprisingly inconvenient to compute! Compare against the normalization factor for the 3D Phong shading model (again at normal incidence):
 \cos\theta_i \Measure\Dir_i &= \int_{0}^{2 \pi} \int_{0}^{\pi/2} \Bsdf(\Dir_i \leftrightarrow \Dir_o) \cos\theta_i \sin\theta_i \Measure\theta_i \Measure\phi_i &= \int_{0}^{2 \pi} \int_{0}^{\pi/2} c \cos\theta_i^{n + 1} \sin\theta_i \Measure\theta_i \Measure\phi_i &= c \frac{2 \pi}{n + 2},") from which we immediately obtain
from which we immediately obtain
 which is significantly simpler.
which is significantly simpler.
What happened? The main difference to the 2D case is the additional factor of  inside the hemispherical integral, which is missing in the hemicircular integral. The reason for this is that we incur a Jacobian when we go from integration w.r.t. solid angle to integration in spherical coordinates. However, we incur no such Jacobian when we go from integration w.r.t. plane angles to integration in polar coordinates. This missing sine is what makes it impossible to derive closed-form sampling routines or even normalization factors for many 3D BRDFs in 2D, requiring different BRDFs in 2D.
inside the hemispherical integral, which is missing in the hemicircular integral. The reason for this is that we incur a Jacobian when we go from integration w.r.t. solid angle to integration in spherical coordinates. However, we incur no such Jacobian when we go from integration w.r.t. plane angles to integration in polar coordinates. This missing sine is what makes it impossible to derive closed-form sampling routines or even normalization factors for many 3D BRDFs in 2D, requiring different BRDFs in 2D.
Indeed, attempting to derive a sampling technique for the Phong Shading Model in 2D using the inversion method will fail; the CDF of this BRDF has a solution in terms of the hypergeometric function, which is inconvenient if not impossible to invert analytically.
The Phong Shading Model is not a particularly good model, so we don't lose out on a whole lot if we cannot represent it in 2D. We will look at a better model for glossy reflection in the next subsection.
Microfacet Models for Rough Mirrors
Microfacet models represent the current state-of-the-art in appearance models for glossy reflection and refraction. They model glossy surfaces as consisting of very small mirror facets that are indiviually smooth. For a distant observer, the facets "blend together" and the aggregate scattering of the surface becomes glossy, even though the facets are mirror-like individually. The distribution of facet orientations (the microfacet distribution) then determines the look of the aggregate scattering profile. Microfacet models for reflection are of the form
 = \frac{D(\HalfDir)G(\Dir_i, \Dir_o, \HalfDir)}{4 \cos\theta_i \cos\theta_o},") where
where  is the half vector (i.e.
is the half vector (i.e. /||\Dir_i + \Dir_o||") ),
),  is the microfacet distribution and
is the microfacet distribution and  is the shadowing-masking term.
is the shadowing-masking term.
As a first step, we need a microfacet distribution that is normalizable and samplable in 2D. Walter et al. present Beckmann, Phong and GGX as three possible choices for the microfacet distribution. We've already established that Phong is not samplable in 2D, and unfortunately neither are Beckmann and GGX. Similar to the Phong Shading Model we've looked at previously, the missing sine in the 2D integrand makes it either not possible to invert the integral or to compute it in the first place.
Therefore, we need a replacement microfacet distribution in 2D that's Gaussian-like, has controllable glossiness and is easily samplable. An interesting choice is to use a logistic distribution, which is an easily samplable Gaussian-like distribution. Brent Burley originally showed me this trick (thanks Brent!), and it's an extremely useful tool to keep around for when you need something that's Gaussian-like but integrable.
The logistic microfacet distribution, normalized to ![[-\pi/2, \pi/2]](prerendered/inline-70-1.png "[-\pi/2, \pi/2]") range, is
range, is
 = \frac{1}{4s}\coth\left(\frac{\pi}{4s}\right)\sech^2\left(\frac{\theta}{2s}\right),") where
where  is a roughness parameter. Skipping the derivation, the corresponding sampling method is
is a roughness parameter. Skipping the derivation, the corresponding sampling method is
 = 2s\, \arctanh\left((2 \xi - 1)\,\tanh\left(\frac{\pi}{4s}\right)\right).") The shadowing-masking term poses a bigger problem, however. We would need to derive an appropriate term for the logistic microfacet distribution using e.g. the Smith shadowing function; however, we will avoid this term altogether by cheating a little bit.
The shadowing-masking term poses a bigger problem, however. We would need to derive an appropriate term for the logistic microfacet distribution using e.g. the Smith shadowing function; however, we will avoid this term altogether by cheating a little bit.
The shadowing-masking term consists of two parts: A shadowing term that removes all light interacting more than once with the microfacets, and a masking term that accounts for hidden microfacet orientations. The shadowing term is unwanted, because it is a limitation of Microfacet theory and causes energy loss at higher roughnesses. We will opt to remove this term, essentially squeezing the missing multiply scattered light into the first bounce. The microfacet BRDF will have the wrong shape, but it will conserve energy.
On the other hand, the masking term is required to make the model energy conserving, so we cannot remove it. Instead, we will importance sample it, following Heitz and d'Eon. The idea is simple: We only sample those normals from the microfacet distribution that do not face away from the incident ray. The sampling distribution is additionally weighted by the projected area of the microfacets, causing the sampling pdf to cancel with the masking term.
In 2D, this technique becomes incredibly simple: If the angle of the incident ray was  , then the angles of visible normals are contained in the interval
, then the angles of visible normals are contained in the interval ![[\ThetaMin, \ThetaMax]](prerendered/inline-73-1.png "[\ThetaMin, \ThetaMax]") , where
, where
 - \frac{\pi}{2} \ThetaMax &= \min(\theta_o, 0)\, + \frac{\pi}{2}.") All we then need to do is to importance sample a normal
All we then need to do is to importance sample a normal  with angle in
with angle in ![[\ThetaMin, \ThetaMax]](prerendered/inline-75-1.png "[\ThetaMin, \ThetaMax]") and probability proportional to
and probability proportional to \cos\theta")
Unfortunately, the added  term to account for projected microfacet area makes even the logistic distribution unsamplable. Since I care more for visuals than physical correctness in this project, I will commit the offense of removing the
term to account for projected microfacet area makes even the logistic distribution unsamplable. Since I care more for visuals than physical correctness in this project, I will commit the offense of removing the  term and only sampling visible normals from the microfacet distribution itself. This will be incorrect for large roughness values, but it will suffice for our purposes.
term and only sampling visible normals from the microfacet distribution itself. This will be incorrect for large roughness values, but it will suffice for our purposes.
For reference, to sample a microfacet normal in ![[\ThetaMin, \ThetaMax]](prerendered/inline-79-1.png "[\ThetaMin, \ThetaMax]") proportional to the logistic microfacet distribution, we use the inverse CDF
proportional to the logistic microfacet distribution, we use the inverse CDF
 = 2s\, \arctanh\left((1 - \xi)\,\tanh\left(\frac{\ThetaMin}{2s}\right) + \xi\,\tanh\left(\frac{\ThetaMax}{2s}\right)\right).") After sampling a microfacet normal using the formula above, we proceed as if we had hit a mirror facet with that normal and reflect off of it (this is an analog sampling algorithm). The resulting sampling code is very simple and proceeds as follows:
After sampling a microfacet normal using the formula above, we proceed as if we had hit a mirror facet with that normal and reflect off of it (this is an analog sampling algorithm). The resulting sampling code is very simple and proceeds as follows:
float sampleVisibleNormal(float s, float xi, float thetaMin, float thetaMax) {
float a = tanh(thetaMin/(2.0*s));
float b = tanh(thetaMax/(2.0*s));
return 2.0*s*atanh(a + (b - a)*xi);
}
vec2 sampleRoughMirror(vec2 w_o, float s) {
float thetaMin = max(asin(w_o.x), 0.0) - PI_HALF;
float thetaMax = min(asin(w_o.x), 0.0) + PI_HALF;
float thetaM = sampleVisibleNormal(s, rand(), thetaMin, thetaMax);
vec2 m = vec2(sin(thetaM), cos(thetaM));
return m*(dot(w_o, m)*2.0) - w_o;
}
Rendered images of an example scene with this rough mirror brdf are shown below.




A beam of light striking a flat surface with a rough mirror material. The roughness of the material increases from left to right.
Microfacet Models for Rough Dielectrics
Rough refraction is very easy to add on top of the rough reflection model presented previously. A microfacet model for refraction looks as follows
 = \frac{F(\Dir_i, \HalfDir)D(\HalfDir)G(\Dir_i, \Dir_o, \HalfDir)}{4 \cos\theta_i \cos\theta_o},") where
where  is a Fresnel term and
is a Fresnel term and  is the generalized half vector. We won't concern ourselves with the specfics of this model, since we can directly arrive at an analog sampling algorithm for it following the rough mirror case. We first sample a microfacet normal as before, and then simply treat it as a smooth dielectric with that orientation, probabilistically refracting or reflecting off of it. The sampling code then looks like this
is the generalized half vector. We won't concern ourselves with the specfics of this model, since we can directly arrive at an analog sampling algorithm for it following the rough mirror case. We first sample a microfacet normal as before, and then simply treat it as a smooth dielectric with that orientation, probabilistically refracting or reflecting off of it. The sampling code then looks like this
vec2 sampleRoughDielectric(vec2 w_o, float ior, float s) {
float thetaMin = max(asin(w_o.x), 0.0) - PI_HALF;
float thetaMax = min(asin(w_o.x), 0.0) + PI_HALF;
float thetaM = sampleVisibleNormal(s, rand(), thetaMin, thetaMax);
vec2 m = vec2(sin(thetaM), cos(thetaM));
float woDotM = dot(w_o, m);
float eta = woDotM < 0.0 ? ior : 1.0/ior;
float Fr = dielectricReflectance(eta, w_o);
float cosThetaT = sqrt(1.0 - eta*eta*w_o.x*w_o.x);
if (rand() < Fr)
return 2.0*woDotM*m - w_o;
else
return (etaM*woDotM - cosThetaT)*m - etaM*w_o;
}
Rendered images of an example scene with this rough dielectric material are shown below.




A beam of light striking a flat surface with a rough dielectric material. The roughness of the material increases from left to right.
Light Transport on the GPU
In the previous sections, we've stated a mathematical description of 2D light transport and described a numerical algorithm to solve it. We also looked at various shading models needed to compute the reflectence of various surfaces. Having all of these blocks in place, I will now describe how we can map this algorithm to the GPU as well as a few problems that can arise when implementing this approach.
As a sidenote, I should mention that the WebGL version of this project is a lot smaller in scope than its native C++ predecessor. The reason is that WebGL is quite limited, and I wasn't able to implement an efficient intersection acceleration structure that would have allowed rendering more complex scenes. Therefore, the intersection code is very primitive and tests intersection against all objects in the scene, limiting the geometric complexity by quite a bit. To hide some of these deficiencies, I implemented constructive solid geometry operations to build up different kinds of lenses from basic primitives. It won't win any awards, but hey! It works.
Wavefront Tracing
A straightforward pseudo-code implementation the light-tracing algorithm we've looked at previously could look something like this:
for i = 1 to N:
x_i, w_i = sampleLe()
for j = 1 to p:
x_i' = raytrace(x_i, w_i)
w_i' = sampleBrdf(x_i', w_i)
drawLine(x_i, x_i')
x_i, w_i = x_i', w_i'
Here, N is the number of samples we allocate to the estimator, and p is the maximum length of the light paths we want to simulate. This code simply traces N samples, starting out by sampling an initial position on the light source and propagating by raytracing, followed by BRDF sampling (as discussed in the previous section). Every segment of the path is splatted to the image plane, i.e. we add the sample to all pixel estimators we have at once. After we're done, the pixels of the image produced by this algorithm need to be scaled by a factor of Le/N to obtain the final rendered image, where Le is the power of the light source. This makes sure the image doesn't get brighter if we use more samples.
A pure CPU implementation of this algorithm is very easy to write, but it would immediately bottleneck inside the drawLine function. GPUs happen to be extremely good at drawing many lines very quickly, so a second attempt is to use GPU acceleration and offload the drawLine call to the GPU. In order to offset the overhead associated with a draw call, we postpone the draw operation and gather multiple lines from different samples into large batches and send as many of them to the GPU at once as we can afford. A simplistic implementation of this could look like so:
for i = 1 to N/M:
lines = []
for k = 1 to M:
x_i, w_i = sampleLe()
for j = 1 to p:
x_i' = raytrace(x_i, w_i)
w_i' = sampleBrdf(x_i', w_i)
lines.append([x_i, x_i'])
x_i, w_i = x_i', w_i'
gpuDraw(lines)
Here, M is the batch size that we can afford. With a large batch size and a language such as C++ in combination with SIMD and multithreading, the CPU side will still trace rays fast enough to bottleneck on the draw call, at least on my GPU (a GTX480). Because the GPU can render asynchronously, we can trace the next batch of rays as the current batch is being rasterized to maximize efficiency, but most likely this is as fast as we can go - the hardware just isn't much faster.
Being bottlenecked on the hardware is generally a good thing, and in a normal world that would be the end of it. However, in order to turn this into a web demo, we need to face the problem of JS: A language that isn't particularly fast, doesn't have SIMD and only has basic multithreading support, moving the bottleneck back to the CPU side. Therefore, our best bet is to offload all of the processing to the GPU, including raytracing and scattering, in order to get the best performance even inside the browser.
Our first attempt is to keep the same layout as the CPU code, and simply parallelize the inner loop over the batch using the GPU. This ends up looking something like this:
for i = 1 to N/M:
gpuParallelFor(1 to M):
x_i, w_i = sampleLe()
for j = 1 to p:
x_i' = raytrace(x_i, w_i)
w_i' = sampleBrdf(x_i', w_i)
drawLine(x_i, x_i')
x_i, w_i = x_i', w_i'
I've used gpuParallelFor to stand for a shader invocation (e.g. drawing a quad or a VBO), meaning that the entire inner loop over p is one big shader. This has several issues: First of all, GPUs don't particularly like branches (especially old ones) and will be very insistent to unroll the inner loop over p. WebGL in particular even forces you to use loops with constant upper bounds so that all loops can be unrolled. This means that a) we cannot specify the light path length at runtime, and b) the WebGL shader compiler will essentially copy paste the loop body p times to get the final shader code. Even for modest values of p (say, 12), this creates a massive shader that will take incredibly long to compile and will even exceed instruction limits on some platforms. A second problem is that we cannot draw multiple lines from a vertex or fragment shader, and given even a modest value for p there are only expensive workarounds we can do.
A different approach is outlined in the paper Megakernels Considered Harmful by Laine et al. It describes a lot of useful techniques (most of which are not doable in WebGL), but the most useful takeaway is the idea of swapping the two loops over M and p. Consider the following:
for i = 1 to N/M:
gpuParallelFor(1 to M): x_i, w_i = sampleLe()
for j = 1 to p:
gpuParallelFor(1 to M): x_i' = raytrace(x_i, w_i)
gpuParallelFor(1 to M): w_i' = sampleBrdf(x_i', w_i)
gpuParallelFor(1 to M): drawLine(x_i, x_i')
x_i, w_i = x_i', w_i'
We split the "megakernel" inner loop from 1 to p into small operations (raytrace, sample, draw, etc.), each of which gets executed by a single, small shader. We batch these operations, always executing them for M rays in parallel.
The advantages of this approach are that we can set an arbitrarily high path length without generating increasingly large and unwieldy shaders. This also nicely solves the problem of having to draw multiple lines in a single shader invocation: We only ever extend the light paths by one bounce per iteration. Therefore, we only have to draw one line per path in each iteration of the inner loop, amounting to a single draw call of M lines per inner iteration, mapping nicely to the GPU.
The drawbacks of this approach are that we need to store all information to memory that needs to be passed from one operation to the next. In WebGL, all of this needs to be done via textures and multi-attachment render targets. In some cases, we need to pass more information than what is reasonable with render targets; in particular, I had to combine the raytrace and sampleBrdf operations into a single shader, since a lot of intersection info needs to be passed between these two stages.
At runtime, the state that needs to be passed between shader stages fits into four float RGBA textures: Two RGBA textures for the current and next position/direction pair (x_i, w_i) and (x_i', w_i'), one texture for the random number generator state and one texture containing the path throughput and the photon wavelength.
Overcoming Rasterization Bias
When writing a straightforward implementation of this light tracer with GPU rasterization, there's an interesting artifact we will encounter. It is best demonstrated in a very simple test scene, shown below. The scene consists of a single point light in empty space, with no walls around it. In such a simple scenario we can compute an analytic solution to what the fluence should look like, shown on the left. However, if we render this scene with GPU rasterization, we get something slightly different, shown on the right:


The fluence of a point light. The reference solution (left) looks different from a naive GPU rasterization method (right) due to rasterization bias.
The effect that we see here is something I call rasterization bias. When we posed the fluence rendering problem at the beginning of this article, we "blurred" the fluence with a pixel reconstruction filter to make efficient rendering tractable. I used a box reconstruction filter, since that is all we can get out of the GPU; however, standard rasterization will not even give us that. In order for our algorithm to be correct, we need the GPU to splat an infinitesimal line to pixels with finite area (left image). However, what it actually does is splat a line with finite area to infinitesimal pixels - i.e. it will "turn on" all pixel whose center lies within a one-pixel-thick line (right image):

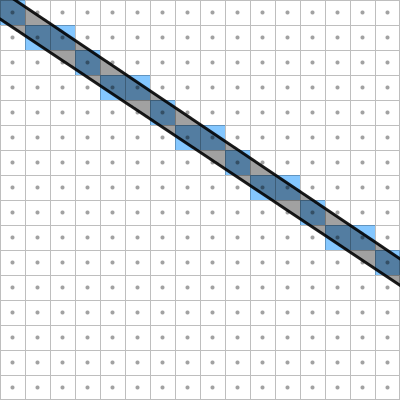
The correctness of our algorithm relies on rasterizing an infinitesimal line with a perfext box filter (left). However, GPU rasterization renders a line with finite area to infinitesimal pixels (right), leading to rasterization bias.
This is a bit of a problem. The GPU is capable of doing the correct rasterization for our problem, but that solution is more commonly known as anti-aliasing and is really quite expensive when drawing a lot of lines. On top of that, there's no reliable way of turning on anti-aliasing in WebGL, and our rendered image would look wrong wherever anti-aliasing is not available. The alternative solution is, of course, to cheat a little bit.
Looking at the image with rasterization bias, we can see that the bias is not uniform; it is worst for lines close to diagonal, and not present for horizontal and vertical lines. Therefore, we first draw a few lines at different orientations and magnify them to see how they differ:
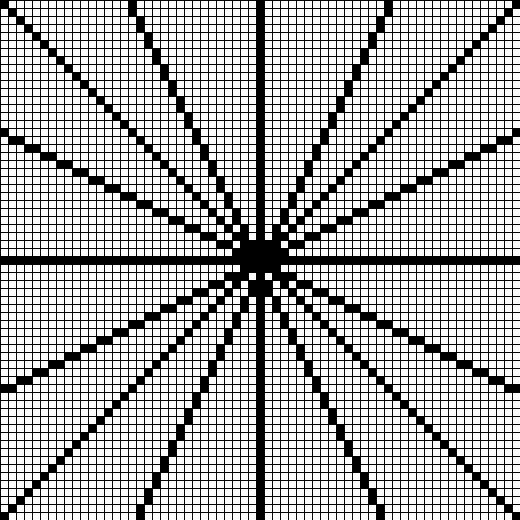
GPU rasterization rules ensure that lines either have exactly one pixel per row or exactly one pixel per column, depending on whether their vertical extent is longer than their horizontal extent.
The first insight from this image is that lines rasterized on the GPU either cover a pixel completely or don't cover it at all. More importantly, a line always draws exactly one pixel per row if its vertical side is longer than its horizontal side, and exactly one pixel per column if its horizontal side is longer than its vertical side. Therefore, a line with pixel dimensions ") turns on exactly
turns on exactly ") pixels, i.e. the length in pixels of the longest side.
pixels, i.e. the length in pixels of the longest side.
In our light tracer, the energy transferred to the image plane by a path segment carrying a radiance of  would be exactly equal to the number of covered pixels if we use GPU rasterization. On the other hand, the same path segment rasterized with a box filter transfers exactly
would be exactly equal to the number of covered pixels if we use GPU rasterization. On the other hand, the same path segment rasterized with a box filter transfers exactly  to the image - i.e., just the length of the line. We can see that these two quantities are not equal: At near horizontal or vertical orientation of the line they are close, but at perfectly diagonal orientation the GPU rasterized line transfers only about 70% of the energy to the image plane compared to the box-filtered version, which explains the darkening.
to the image - i.e., just the length of the line. We can see that these two quantities are not equal: At near horizontal or vertical orientation of the line they are close, but at perfectly diagonal orientation the GPU rasterized line transfers only about 70% of the energy to the image plane compared to the box-filtered version, which explains the darkening.
Therefore, a simple bias correction that does not rely on anti-aliasing is to simply multiply the radiance of each path segment in the vertex shader by a bias correction factor before rasterizing them. This factor is simply the ratio of the two formulas given above:
}.")
In general, the images produced by this approach will be practically indistinguishable from the reference box filter solution, while being much cheaper than if we had used full-blown anti-aliasing. For the point light example from before, here's again the analytic solution (left) and our light traced solution with cheap GPU rasterization and bias correction (right):

The fluence of a point light. The reference solution (left) is practically indistinguishable from our GPU rasterized version (right) with bias correction applied.
Conclusion and Outlook
This has been a rather lengthy outline of some of the math and programming that has gone into this project. I skipped out on a lot of the details and some of the text might be unclear, but feel free to write me an email if you need clarification on something. All of the code is available on Github and accepts patches in case you encounter any bugs. I will most likely move on and not invest much more time into this project, but if you have suggestions for simple improvements, feel free to send me an email. Also, if you do anything cool with the code, I'm very interested to hear about it.
For future work, it would be interesting to add full support for participating media to the renderer. Especially in conjunction with 2D fluid simulation, this has potential for generating very cool images of volumetric scattering in rising smoke or fire, or caustics in water simulations. Adding participating media does change some of our earlier performance considerations, as radiance is no longer constant along rays. I do have an implementation of homogeneous participating media in my C++ version (an example image is shown below), but heterogeneous media are most likely very challenging to reconcile with our rendering approach and create opportunity for some interesting research. I also don't have a rigorous derivation of radiative transfer in 2D, so there is definitely still some work to be done.

Preliminary results of an extension of this project to homogeneous participating media. Here, a sphere containing a milk-like homogeneous medium is lit by a laser beam.
Another interesting addition to this project would be to extend it to transient rendering, similar to a recent project by Jarabo et al.. Essentially, we choose the shutter speed of the camera to be so short that it can capture light as it slowly spreads through the scene over time. Especially in 2D this promises to generate some interesting images, and wouldn't require much modification to our existing rendering approach.
References
- Theory, Analysis and Applications of 2D Global Illumination
W. Jarosz, V. Schönefeld, L. Kobbelt, H. W. Jensen - Path Space Regularization for Holistic and Robust Light Transport
A. S. Kaplanyan, C. Dachsbacher - Light Transport On Path-Space Manifolds
W. Jakob - Microfacet Models for Refraction through Rough Surfaces
B. Walter, S, R. Marschner, H. Li, K. E. Torrance - Importance Sampling Microfacet-Based BSDFs using the Distribution of Visible Normals
E. Heitz, E. d'Eon - Megakernels Considered Harmful: Wavefront Path Tracing on GPUs
S. Laine, T. Karras, T. Aila - A Framework for Transient Rendering
A. Jarabo, J. Marco, A. Muñoz, R. Buisan, W. Jarosz, D. Gutierrez